
Debido a que los sitios web modernos son complicados y con frecuencia dependen de contenido dinámico, ArchiveBox archiva los sitios en varios formatos diferentes, más allá de lo que los servicios públicos de archivo como Archive.org y Archive.is pueden guardar.
ArchiveBox importa una lista de URL de stdin, url remoto o archivo, luego agrega las páginas a una carpeta de archivo local usando wget para crear un clon html navegable, youtube-dl para extraer medios, y una instancia completa de Chrome para PDF, captura de pantalla, y volcados de DOM, y más ...
El uso de múltiples métodos y el navegador dominante en el mercado para ejecutar JS garantiza que podamos guardar incluso los sitios web más complejos y meticulosos en al menos unos pocos -calidad, formatos de datos a largo plazo.
### Puede importar enlaces desde:
- Pocket, Pinboard, Instapaper
- RSS, XML, JSON o listas de texto sin formato
- Historial del navegador o marcadores (Chrome, Firefox, Safari, IE, Opera y más)
- Shaarli, Delicious, Reddit Saved Post, Wallabag, Unmark.it y cualquier otro ¡otro texto con enlaces en él!
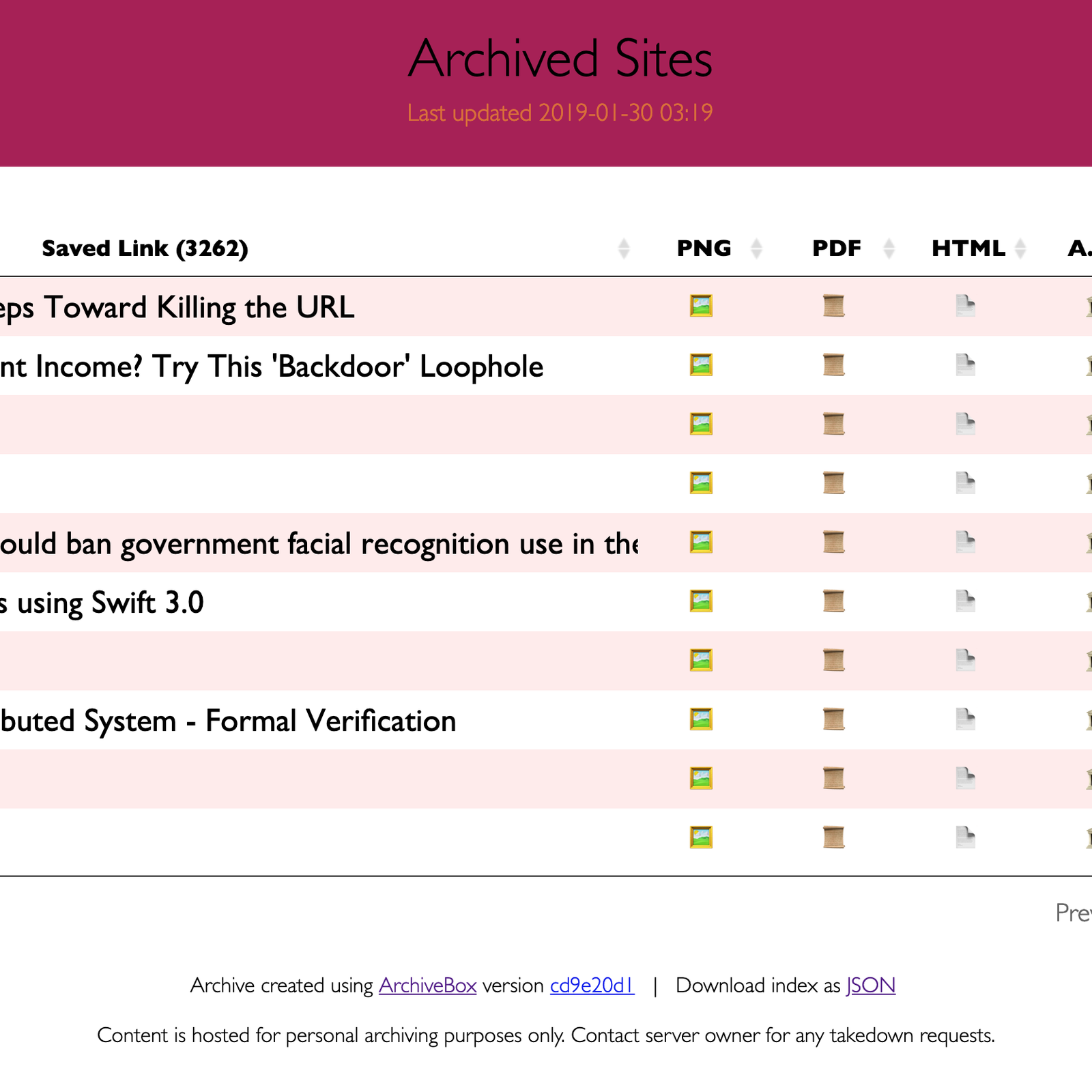
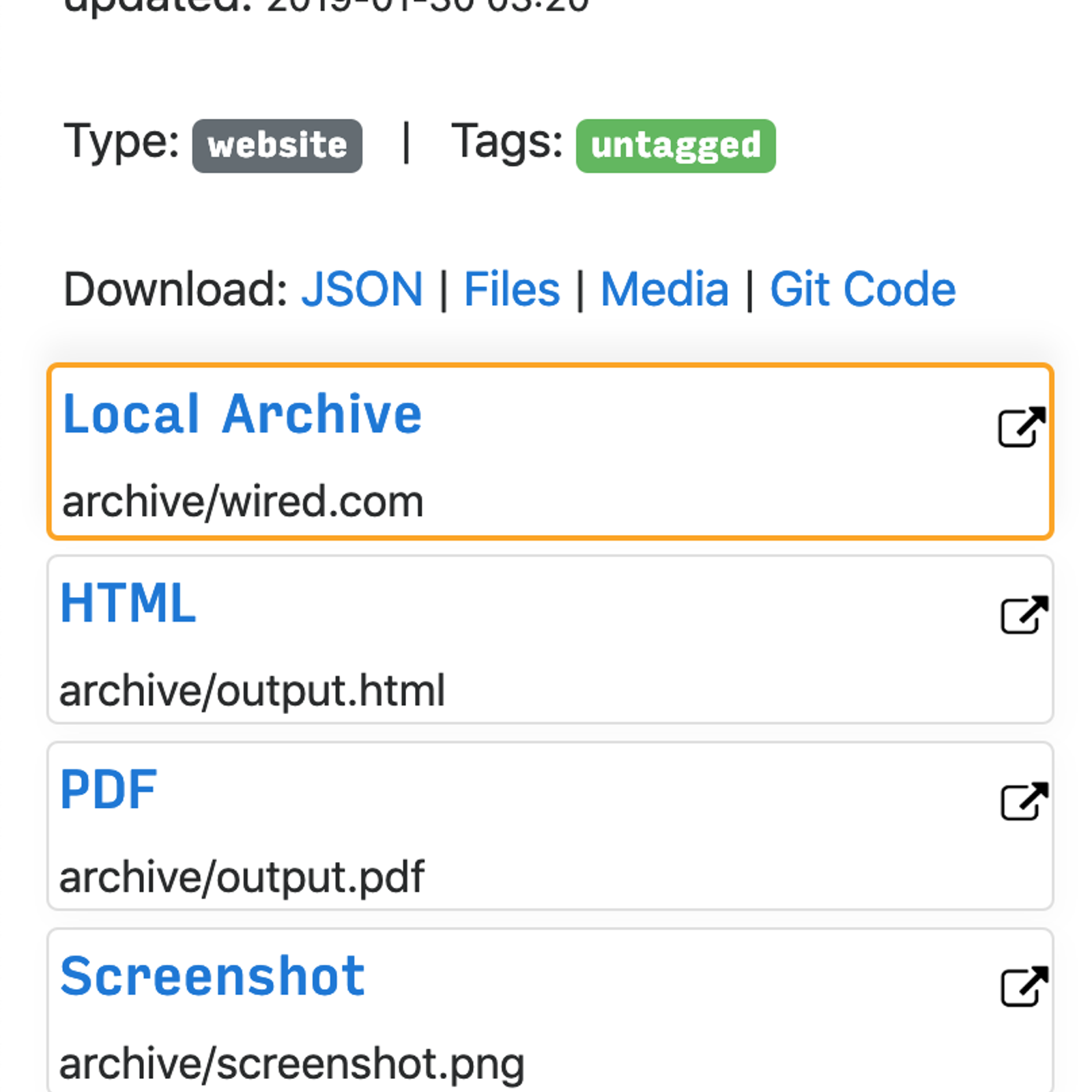
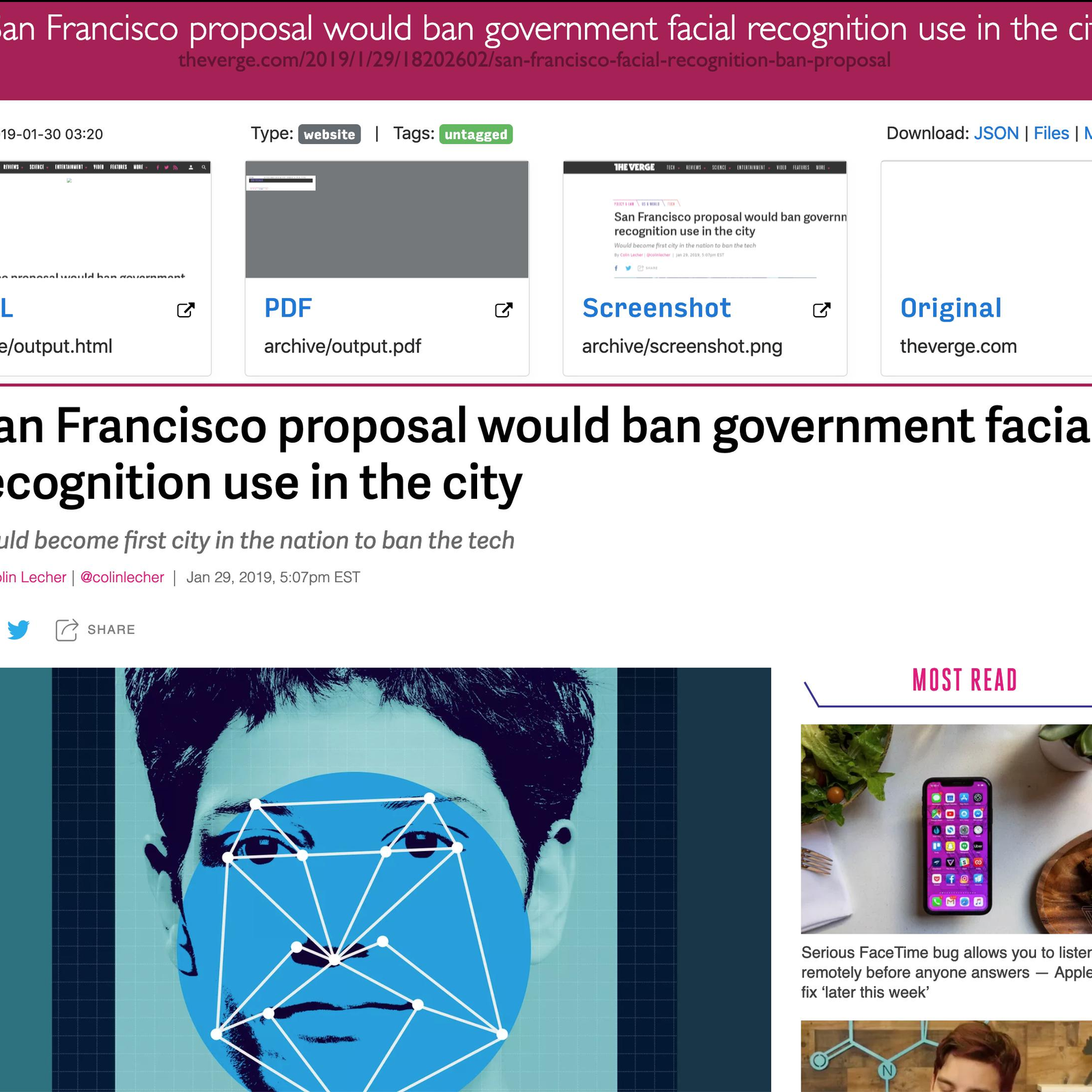
### Puede guardar estas cosas para cada sitio:
-` favicon.ico` favicon del sitio
- `example.com / page-name.html` wget clon del sitio, con .html adjunto si no está presente
-` output.pdf` Impreso PDF del sitio utilizando Chrome sin cabeza
- `screenshot.png` 1440x900 captura de pantalla del sitio usando Chrome sin cabeza
-` output.html` DOM Volcado del HTML después del renderizado usando Chrome sin cabeza
- `archive.org. txt` Un enlace al sitio guardado en archive.org
- `warc /` para html + gzipped warc file & lt; timestamp & gt; .gz
- `media /` cualquier mp4,
mp3, subtítulos y metadatos encontrados usando youtube-dl
- `git /` clon de cualquier repositorio de enlaces de github, bitbucket o gitlab
- `index.html` & amp; `index.json` archivos de índice HTML y JSON que contienen metadatos y detalles
El archivo es aditivo, por lo que puede programar`. / archive` para que se ejecute regularmente y obtenga nuevos enlaces en el índice .
Todo el contenido guardado es estático e indexado con archivos JSON, por lo que vive para siempre & amp; es fácilmente analizable, no requiere un backend que se ejecute siempre.
 Pocket
Pocket
 Wget
Wget
 HTTrack
HTTrack
 Wayback Machine
Wayback Machine
 wallabag
wallabag
 Pinboard
Pinboard
 Archive.is
Archive.is
 Internet Archive
Internet Archive
 Evernote Web Clipper
Evernote Web Clipper
 Stash.ai
Stash.ai
 PageArchiver
PageArchiver
 SiteSucker
SiteSucker
 Webrecorder
Webrecorder
 SiteCrawler
SiteCrawler
 Archive-It
Archive-It
 Archivarix Website Downloader
Archivarix Website Downloader
 Fossilo
Fossilo
 Web Dumper
Web Dumper
Discontinuado Último compromiso el 5 de mayo de 2013. Consulte https://github.com/gildas-lormeau/Scrapbook-for-SingleFile