
El propósito de Luigi es abordar todas las tuberías típicamente asociadas con procesos por lotes de larga ejecución. Desea encadenar muchas tareas, automatizarlas y se producirán fallas. Estas tareas pueden ser cualquier cosa, pero generalmente son tareas de larga duración como trabajos de Hadoop, volcado de datos a / desde bases de datos, algoritmos de aprendizaje automático o cualquier otra cosa.
Hay otros paquetes de software que se centran en aspectos de nivel inferior de procesamiento de datos, como Hive, Pig, o en cascada. Luigi no es un marco para reemplazar estos. En su lugar, le ayuda a unir muchas tareas, donde cada tarea puede ser una consulta Hive, un trabajo Hadoop en Java, un trabajo Spark en Scala o Python, un fragmento de código de Python, descargando una tabla de una base de datos, o cualquier otra cosa. Es fácil construir tuberías de larga duración que comprenden miles de tareas y tardan días o semanas en completarse. Luigi se encarga de gran parte de la gestión del flujo de trabajo para que pueda centrarse en las tareas en sí mismas y en sus dependencias ...
Puede crear casi cualquier tarea que desee, pero Luigi También viene con una caja de herramientas de varias plantillas de tareas comunes que utiliza. Incluye soporte para ejecutar trabajos de Python mapreduce en Hadoop, así como trabajos de Hive y Pig. También incluye abstracciones del sistema de archivos para HDFS y archivos locales que garantizan que todas las operaciones del sistema de archivos sean atómicas. Esto es importante porque significa que su canalización de datos no se bloqueará en un estado que contenga datos parciales.
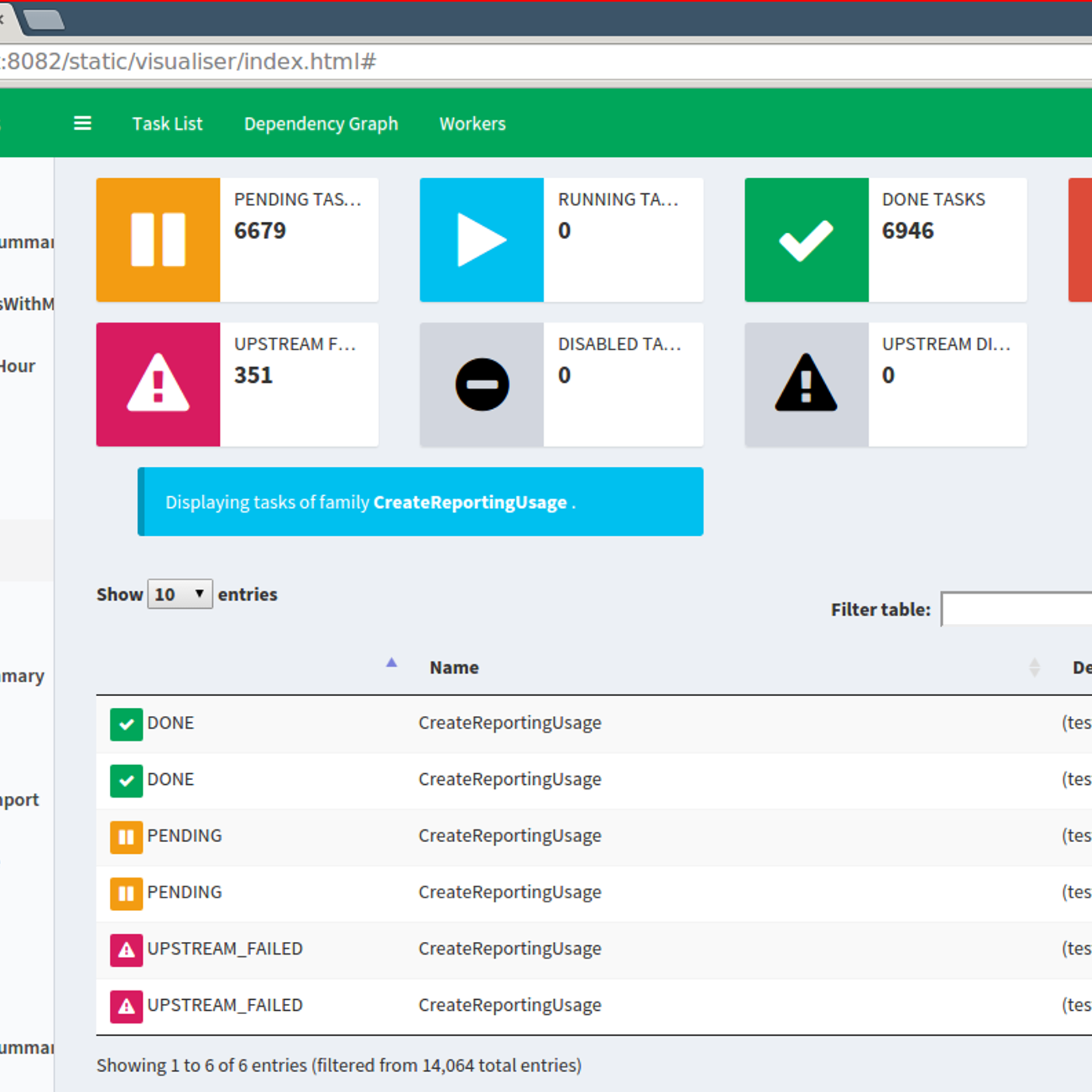

 Apache Airflow
Apache Airflow
 Azkaban
Azkaban
 StackStorm
StackStorm
 Apache Oozie
Apache Oozie
Luigi Comentarios
Todavía no hay comentarios